【So-VITS/VITS】炼丹速通指南
作者:[涣宵]
## 使用规约
**SoftVC VITS Singing Voice Conversion 使用规约:**
**Warning:请自行解决数据集授权问题,禁止使用非授权数据集进行训练!任何由于使用非授权数据集进行训练造成的问题,需自行承担全部责任和后果!与仓库、仓库维护者、svc develop team 无关!**
1. 本项目是基于学术交流目的建立,仅供交流与学习使用,并非为生产环境准备。
2. 任何发布到视频平台的基于 sovits 制作的视频,都必须要在简介明确指明用于变声器转换的输入源歌声、音频,例如:使用他人发布的视频 / 音频,通过分离的人声作为输入源进行转换的,必须要给出明确的原视频、音乐链接;若使用是自己的人声,或是使用其他歌声合成引擎合成的声音作为输入源进行转换的,也必须在简介加以说明。
3. 由输入源造成的侵权问题需自行承担全部责任和一切后果。使用其他商用歌声合成软件作为输入源时,请确保遵守该软件的使用条例,注意,许多歌声合成引擎使用条例中明确指明不可用于输入源进行转换!
4. 继续使用视为已同意本仓库 (https://link.zhihu.com/?target=https%3A//github.com/svc-develop-team/so-vits-svc/blob/4.0/README_zh_CN.md) 所述相关条例,本仓库 (https://link.zhihu.com/?target=https%3A//github.com/svc-develop-team/so-vits-svc/blob/4.0/README_zh_CN.md) 已进行劝导义务,不对后续可能存在问题负责。
5. 如将本仓库代码二次分发,或将由此项目产出的任何结果公开发表 (包括但不限于视频网站投稿),请注明原作者及代码来源 (此仓库)。
6. 如果将此项目用于任何其他企划,请提前联系并告知本仓库作者,十分感谢。
## 相关法律
[《中华人民共和国民法典》](https://link.zhihu.com/?target=http%3A//www.npc.gov.cn/npc/c30834/202006/75ba6483b8344591abd07917e1d25cc8.shtml)
**第一千零一十八条** 自然人享有肖像权,有权依法制作、使用、公开或者许可他人使用自己的肖像。
肖像是通过影像、雕塑、绘画等方式在一定载体上所反映的特定自然人可以被识别的外部形象。
**第一千零一十九条** 任何组织或者个人不得以丑化、污损,或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意,不得制作、使用、公开肖像权人的肖像,但是法律另有规定的除外。
未经肖像权人同意,肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。
**第一千零二十条** 合理实施下列行为的,可以不经肖像权人同意:
(一)为个人学习、艺术欣赏、课堂教学或者科学研究,在必要范围内使用肖像权人已经公开的肖像;
(二)为实施新闻报道,不可避免地制作、使用、公开肖像权人的肖像;
(三)为依法履行职责,国家机关在必要范围内制作、使用、公开肖像权人的肖像;
(四)为展示特定公共环境,不可避免地制作、使用、公开肖像权人的肖像;
(五)为维护公共利益或者肖像权人合法权益,制作、使用、公开肖像权人的肖像的其他行为。
**第一千零二十一条** 当事人对肖像许可使用合同中关于肖像使用条款的理解有争议的,应当作出有利于肖像权人的解释。
**第一千零二十二条** 当事人对肖像许可使用期限没有约定或者约定不明确的,任何一方当事人可以随时解除肖像许可使用合同,但是应当在合理期限之前通知对方。
当事人对肖像许可使用期限有明确约定,肖像权人有正当理由的,可以解除肖像许可使用合同,但是应当在合理期限之前通知对方。因解除合同造成对方损失的,除不可归责于肖像权人的事由外,应当赔偿损失。
**第一千零二十三条** 对姓名等的许可使用,参照适用肖像许可使用的有关规定。
对自然人声音的保护,参照适用肖像权保护的有关规定。
## 免责声明
此文是2.0版本,因为前几天电脑中了勒索病毒,硬盘全部格式化,所以现有内容全靠记忆复述,可能有不严谨,错漏的地方,请谨慎阅读和理解。
在本文中出现的有为浏览者提供方便的第三方链接,其内容并不完全代表本人观点,凡是非本人声明且提供的,其造成的各种麻烦与我无关。
希望各位可以少走弯路,快速的、高效的、低成本的训练模型。
封面由AI生成。
---
## 关于训练
训练需要N卡,需要N卡,需要N卡,除非是高端显卡或者是用于深度学习的专业级显卡,我一律推荐云端训练;推理则在本地进行,推理对配置需求不高。
云端训练在Google Colab (需文明上网),我给出的Colab笔记本都是经过排错可以正常运行的。
在Colab你大概率能白嫖一张**Tesla T4**显卡,但是使用时间比较弹性,免费用户每天最长使用时间不超过12小时,所以,你想不间断地训练,可以多注册几个Google账号。
你只需要把采样数据的备份文件和最后训练的模型共享给其他账号,并把共享的文件的快捷方式添加到云端硬盘即可。(关于备份这一步,在Clob笔记本里会和云盘建立硬链接,按着交互顺序来即可。)
私人账号的Google Drive免费容量只有15G,训练集数据比较大的话,你就需要注意硬盘容量,清空掉多余的数据。
Colab笔记本使用方法也很简单,打开即用,基本没什么门槛,如果你还是不太明白,可以看一下具体一点的说明:[免费的GPU——colab使用教程](https://zhuanlan.zhihu.com/p/149233850)
---
**训练集格式建议:统一分割成 2-10 秒的短音频文件,要WAVE格式。**
打包格式普遍为 **(具体项目具体分析)** :
```text
zidingyo.zip
└─── name
├───abcd123.wav
├───...
└───zidingyi_123.wav
```
其他注意事项:
1. 训练中途不能添加或减少训练集。
2. 实际训练出来的效果一般还是要看训练集的质量,比如不能有杂音噪音。
3. 唱歌要看歌曲人声提取地是否干净,还有歌曲难度。
4. 各个项目的模型不通用。
以上标准仅仅是个人建议,实际要求去看项目文档。
## 常用工具
> 仅仅是推荐。
音频自动切片:(https://link.zhihu.com/?target=https%3A//github.com/henrymaas/AudioSlicer)
分离人声-UVR:(https://link.zhihu.com/?target=https%3A//github.com/Anjok07/ultimatevocalremovergui/releases)
分离人声-RipX
伴奏抵消-utagoe
音频编辑-Adobe Audition
免费分离人声网站:(https://link.zhihu.com/?target=https%3A//www.yinziai.com/tools/extract-voice)、(https://link.zhihu.com/?target=https%3A//vocalremover.org/zh/)、(https://link.zhihu.com/?target=https%3A//ezstems.com/)
免费格式转换网站:(https://link.zhihu.com/?target=https%3A//convertio.co/zh/)、(https://link.zhihu.com/?target=https%3A//cloudconvert.com/)、(https://link.zhihu.com/?target=https%3A//www.aconvert.com/cn/audio/)
## 环境搭建
**我不提倡本地训练,所以搭建本地环境仅仅是为了推理。**
云端推理可以跳过环境搭建这一步。
以**So-VITS 4.0**为例子,去项目地址下载项目文件,选个目录解压。
然后安装(https://link.zhihu.com/?target=https%3A//www.python.org/downloads/release/python-3810/)和(https://link.zhihu.com/?target=https%3A//git-scm.com/downloads)
安装后在项目目录的资源管理器窗口鼠标右键Git Bash,输入:
```text
py -3.8 -m pip install -r requirements_win.txt
```
如果提示缺少 Microsoft Visual C++ 14.0 is required,那你就根据命令窗口的提示,去下面链接下载:
(https://link.zhihu.com/?target=https%3A//visualstudio.microsoft.com/visual-cpp-build-tools/)
然后下载“必要模型文件”放入hubert文件夹。
Colab笔记里都能找到下载地址,比如So-VITS 4.0-44的(https://link.zhihu.com/?target=https%3A//huggingface.co/datasets/seq2193/sovits_pretrained/resolve/main/44k/checkpoint_best_legacy_500.pt)、So-VITS 4.0-v2的(https://link.zhihu.com/?target=https%3A//ibm.ent.box.com/shared/static/z1wgl1stco8ffooyatzdwsqn2psd9lrr)、So-VITS 3.0的(https://link.zhihu.com/?target=https%3A//github.com/bshall/hubert/releases/download/v0.1/hubert-soft-0d54a1f4.pt)等。
推理可以直接建个批处理文件,打开WebUI界面操作:
```text
py -3.8 webUI.py
```
注意!如果你选择gpu推理时报错 ↓
```text
异常信息:Expected one of cpu, cuda, ipu, xpu, mkldnn, opengl, opencl, ideep, hip, ve, fpga, ort, xla, lazy, vulkan, mps, meta, hpu, mtia, privateuseone device type at start of device string: gpu 请排障后重试
```
你需要编辑一下webUI.py,找到第62行,把gpu改为cuda,如:
```text
device = gr.Dropdown(label="推理设备,留白则为自动选择cpu和cuda",choices=,value=None)
```
本地推理建议你顺便安装 (https://link.zhihu.com/?target=https%3A//ffmpeg.org/download.html) ,记得配置环境变量。 不会操作就百度。
推理选择CUDA时,如果报错:
```text
Torch not compiled with CUDA enabled
```
说明你可能没安装(https://link.zhihu.com/?target=https%3A//developer.nvidia.com/cuda-toolkit-archive),或者没正确安装torch,根据(https://link.zhihu.com/?target=https%3A//pytorch.org/get-started/locally/)官方文档,你可能需要参考这个指令:
```text
py -3.8 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
```
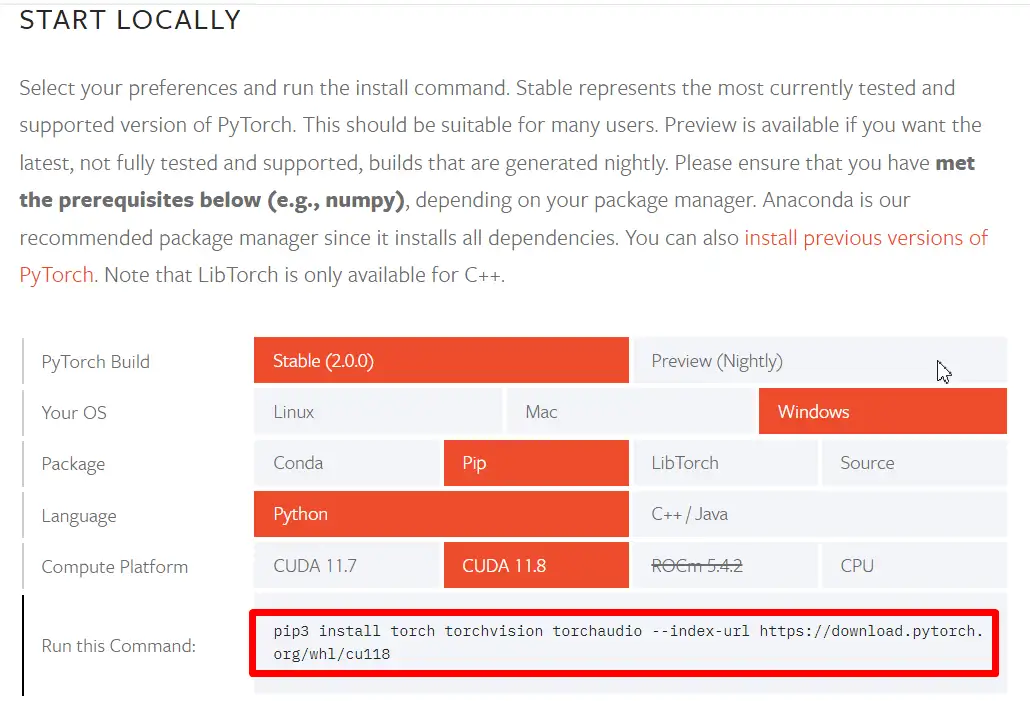
2.0.0版本只最高支持到CUDA 11.8,你另外还可能需要安装(https://link.zhihu.com/?target=https%3A//developer.nvidia.com/rdp/cudnn-download)
最后,随便写个py脚本测试下,看你torch能不能用到CUDA:
```text
import torch
print(torch.__version__)
print(torch.cuda.is_available())
print(torch.backends.cudnn.version())
```

---
## So-VITS 4
项目地址:(https://link.zhihu.com/?target=https%3A//github.com/svc-develop-team/so-vits-svc/tree/4.0)
参考视频:[【【AI翻唱/SoVITS 4.0】手把手教你唱歌给你听~无需配置环境的本地训练/推理教程[懒人整合包]】](https://link.zhihu.com/?target=https%3A//www.bilibili.com/video/BV1H24y187Ko/%3Fshare_source%3Dcopy_web)
Google Colab在线训练:(https://link.zhihu.com/?target=https%3A//colab.research.google.com/drive/1WjOZFyJVdP7-uozL5TKDekqnSB4rmMm-%3Fusp%3Dsharing) (我魔改的速通版)
跟进版本,用aria2c下载大文件。
**4.0版本问题较少,建议优先使用。**
## So-VITS 4.0-Vec768-Layer12
项目地址:(https://link.zhihu.com/?target=https%3A//github.com/svc-develop-team/so-vits-svc/tree/4.0-Vec768-Layer12)
Google Colab在线训练:(https://link.zhihu.com/?target=https%3A//colab.research.google.com/drive/1Ecd-Q2pTSb7uxpl5QVdJlhTOHIqeX7_a%3Fusp%3Dsharing)
没有底模。
## So-VITS 4-v2
项目地址:(https://link.zhihu.com/?target=https%3A//github.com/svc-develop-team/so-vits-svc/tree/4.0-v2)
项目说明:(https://link.zhihu.com/?target=https%3A//github.com/svc-develop-team/so-vits-svc/blob/4.0-v2/README_zh_CN.md)
Google Colab在线训练:(https://link.zhihu.com/?target=https%3A//colab.research.google.com/drive/1D75w3NeZ2Ohzs3a9lM27HcjE_AZ4DRh9%3Fusp%3Dsharing) (我魔改的速通版)
Colab所用预训练模型出自:(https://link.zhihu.com/?target=https%3A//openbayes.com/console/open-tutorials/models/yRMgbIo56um/)
原版训练可能会莫名奇妙报错,应该和环境有关,我设置了一点措施,顺便做了一点汉化,可以用。
打印的错误信息(对号入座) ↓
```text
Traceback (most recent call last):
File "/usr/local/lib/python3.9/dist-packages/torch/multiprocessing/spawn.py", line 69, in _wrap
fn(i, *args)
File "/content/so-vits-svc/train.py", line 117, in run
train_and_evaluate(rank, epoch, hps, , , ,
File "/content/so-vits-svc/train.py", line 194, in train_and_evaluate
for batch_idx, data_dict in enumerate(train_loader):
File "/usr/local/lib/python3.9/dist-packages/torch/utils/data/dataloader.py", line 628, in __next__
data = self._next_data()
File "/usr/local/lib/python3.9/dist-packages/torch/utils/data/dataloader.py", line 1333, in _next_data
return self._process_data(data)
File "/usr/local/lib/python3.9/dist-packages/torch/utils/data/dataloader.py", line 1359, in _process_data
data.reraise()
File "/usr/local/lib/python3.9/dist-packages/torch/_utils.py", line 543, in reraise
raise exception
TypeError: Caught TypeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/usr/local/lib/python3.9/dist-packages/torch/utils/data/_utils/worker.py", line 302, in _worker_loop
data = fetcher.fetch(index)
File "/usr/local/lib/python3.9/dist-packages/torch/utils/data/_utils/fetch.py", line 58, in fetch
data = for idx in possibly_batched_index]
File "/usr/local/lib/python3.9/dist-packages/torch/utils/data/_utils/fetch.py", line 58, in <listcomp>
data = for idx in possibly_batched_index]
File "/content/so-vits-svc/data_utils.py", line 154, in __getitem__
mel = audio.melspectrogram(wav, self.hparams.data).astype(np.float32).T
File "/content/so-vits-svc/modules/audio.py", line 95, in melspectrogram
S = _amp_to_db(_linear_to_mel(np.abs(D), hparams),
File "/content/so-vits-svc/modules/audio.py", line 50, in _linear_to_mel
_mel_basis = _build_mel_basis(hparams)
File "/content/so-vits-svc/modules/audio.py", line 40, in _build_mel_basis
return librosa.filters.mel(hparams.sampling_rate,
TypeError: mel() takes 0 positional arguments but 2 positional arguments (and 3 keyword-only arguments) were given
```
这个版本的依赖环境有点麻烦,建议在云端推理。
因为模型架构完全修改成了(https://link.zhihu.com/?target=https%3A//github.com/zhangyongmao/VISinger2) 架构,torch版本和4.0的不兼容。
除非你不想用CUDA,或者可以浪费一点硬盘空间把装好环境的Python3.8复制一份进去。
操作方法参考环境搭建那部分。
## So-VITS 3
参考视频:[【AI翻唱制作教程】- colab云端训练模型(适用于sovits 3.0)](https://link.zhihu.com/?target=https%3A//www.bilibili.com/opus/771791943827980297)
项目地址:(https://link.zhihu.com/?target=https%3A//github.com/svc-develop-team/so-vits-svc/tree/3.0-32k)
Google Colab 在线训练:(https://link.zhihu.com/?target=https%3A//colab.research.google.com/drive/11zKzy38nFENUbELIE8eiv36ESeObYkOc%3Fusp%3Dsharing) (我魔改的速通版)
48K版:(https://link.zhihu.com/?target=https%3A//colab.research.google.com/drive/1koAB19VkBAE1QCL8A3-j0Q-O51KmlM9T%3Fusp%3Dsharing) (我魔改的速通版)
**使用32K分支**你需要将此文件转存到你的谷歌网盘根目录:
(https://link.zhihu.com/?target=https%3A//drive.google.com/file/d/1nWBzmSD3iKj799ISPodRr02QMMbReqA1/view%3Fusp%3Dsharing)
我修改了resample.py第17行,也就是下面第8行的代码, **防止重采样步骤报错** 。48K版需要自行手动修改。
```text
def process(item):
spkdir, wav_name, args = item
# speaker 's5', 'p280', 'p315' are excluded,
speaker = spkdir.replace("\\", "/").split("/")[-1]
wav_path = os.path.join(args.in_dir, speaker, wav_name)
if os.path.exists(wav_path) and '.wav' in wav_path:
os.makedirs(os.path.join(args.out_dir2, speaker), exist_ok=True)
wav, sr = librosa.load(wav_path)
wav, _ = librosa.effects.trim(wav, top_db=20)
peak = np.abs(wav).max()
if peak > 1.0:
wav = 0.98 * wav / peak
wav2 = librosa.resample(wav, orig_sr=sr, target_sr=args.sr2)
wav2 /= max(wav2.max(), -wav2.min())
save_name = wav_name
save_path2 = os.path.join(args.out_dir2, speaker, save_name)
wavfile.write(
save_path2,
args.sr2,
(wav2 * np.iinfo(np.int16).max).astype(np.int16)
)
```
3.0版本训练时会报错(暂无影响):
```text
TF-TRT Warning: Could not find TensorRT
```
本地推理你无需更改这个。
WebUI开启方式,使用 sovits_gradio.py
* 新建文件夹:checkpoints 并打开
* 在checkpoints文件夹中新建一个文件夹作为项目文件夹,文件夹名为你的项目名称
* 将你的模型更名为model.pth,配置文件更名为config.json,并放置到刚才创建的文件夹下
* 运行 sovits_gradio.py
## DDSP-SVC
项目地址:(https://link.zhihu.com/?target=https%3A//github.com/yxlllc/DDSP-SVC)
项目说明与要求:(https://link.zhihu.com/?target=https%3A//github.com/yxlllc/DDSP-SVC/blob/master/cn_README.md)
参考视频:[【【AI翻唱/整合包】3G显存也能跑,一个小时出模型!全新的歌声转换模型DDSP-SVC】](https://link.zhihu.com/?target=https%3A//www.bilibili.com/video/BV1qM411W7ft/%3Fshare_source%3Dcopy_web)
Google Colab在线训练:[参考视频简介](https://link.zhihu.com/?target=https%3A//colab.research.google.com/drive/1fK08FGlSwEduD9LDvrRJgkhYJPz37f6u%3Fusp%3Dsharing)
如果你使用了Colab在线训练,并且打算下载参考视频里的整合包,你需要去项目地址下载新版本的项目代码来覆盖掉整合包文件。
训练和合成对电脑硬件的要求要低的多,并且训练时长有数量级的缩短。
默认配置适用于GTX-1660 显卡训练 44.1khz 高采样率合成器。
> 值得尝试,配置亲民,训练很快,效果尚可,未来可期。
## VITS Fast Fine-tuning
项目地址:(https://link.zhihu.com/?target=https%3A//github.com/Plachtaa/VITS-fast-fine-tuning)
参考视频:[【VITS】输入视频链接即可克隆说话人音色!无需准备数据集的VITS训练](https://link.zhihu.com/?target=https%3A//www.bilibili.com/video/BV1Jg4y1E7df/%3Fshare_source%3Dcopy_web)
Google Colab在线训练:[参考视频简介](https://link.zhihu.com/?target=https%3A//colab.research.google.com/drive/1pn1xnFfdLK63gVXDwV4zCXfVeo8c-I-0%3Fusp%3Dsharing)
训练集格式要求:(https://link.zhihu.com/?target=https%3A//github.com/Plachtaa/VITS-fast-fine-tuning/blob/main/DATA.MD)
> 用于文字转语音。
## RVC
Retrieval-based-Voice-Conversion-WebUI
项目地址:(https://link.zhihu.com/?target=https%3A//github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI)
参考视频:[【RVC】全新Al变声器一键训练包发布!10分钟克隆你的声音!](https://link.zhihu.com/?target=https%3A//www.bilibili.com/video/BV1pm4y1z7Gm/%3Fshare_source%3Dcopy_web%26vd_source%3Df424d29e56af8c2543498512aede1428)
Google Colab在线训练:(https://link.zhihu.com/?target=https%3A//colab.research.google.com/github/liujing04/Retrieval-based-Voice-Conversion-WebUI/blob/main/Retrieval_based_Voice_Conversion_WebUI.ipynb)
:):):):):):):):):):) :):):):):):):):) 谢谢分享至网站 无奈电脑不给力 666666666666
页:
[1]