Stable Diffusion模型训练(5):经典的微调方案HyperNetworks
!(https://picx.zhimg.com/70/v2-6dfc7c9a0b8f93259b5e2d8a1df9e430_1440w.image?source=172ae18b&biz_tag=Post)作者:正气凛然郭大侠
## 0 论文来源
论文标题:**HYPERNETWORKS**
论文链接:
[https://arxiv.org/abs/1609.09106v3**arxiv.org/abs/1609.09106v3**](https://link.zhihu.com/?target=https%3A//arxiv.org/abs/1609.09106v3)
github代码(推荐使用SD webUI中可集成插件):
[https://github.com/antis0007/sd-webui-multiple-hypernetworks**github.com/antis0007/sd-webui-multiple-hypernetworks**](https://link.zhihu.com/?target=https%3A//github.com/antis0007/sd-webui-multiple-hypernetworks)
## 1. 简述
超网络(HyperNetworks)是Google在16年提出的一种模型微调方案,其主要通过微调小参数模型结构去替代原大模型中的权重矩阵( *这个思路和后面的LoRA的思路相,详见:[最流行的训练方式Lora](https://zhuanlan.zhihu.com/p/632245554)* )。Google将该方案在深度卷积模型和长序列循环网络模型中进行验证。1. 在LSTM中实现了非共享的参数layer效果,在多种生成式下游任务中取得了SOTA的效果,例如:语言模型、机器翻译等。2. 在CNN类结构的图像识别类任务中也取得了SOTA的效果。
!(data/attachment/forum/202307/01/131610tqe37afe9m9emmo1.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/300 "image.png")
## 2. 具体方案
本文分别从两类极端模型结构上进行了超网络效果的验证,即一个是深度模型、一个是循环模型。循环模型每一步特征在参数共享的模型中进行循环传递,这样容易导致梯度消失/梯度爆炸(当然后续有改进方案,例如LSTM、GRU等)。深度卷积模型纵向layer之间不进行参数共享,使得整个模型随着深度的增加变得冗余。超网络介于两者之间,可以看作为一种弹性的参数共享。超网络在两类模型上的具体应用细节如下:
### 2.1 静态超网络:deep CNN中的权重因式分解

A hypernetwork generates the weights for CNN
!(data/attachment/forum/202307/01/131729kusnoyxuowx571ou.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/300 "image.png")
### 2.2 动态超网络:RNN中的自适应权重生成
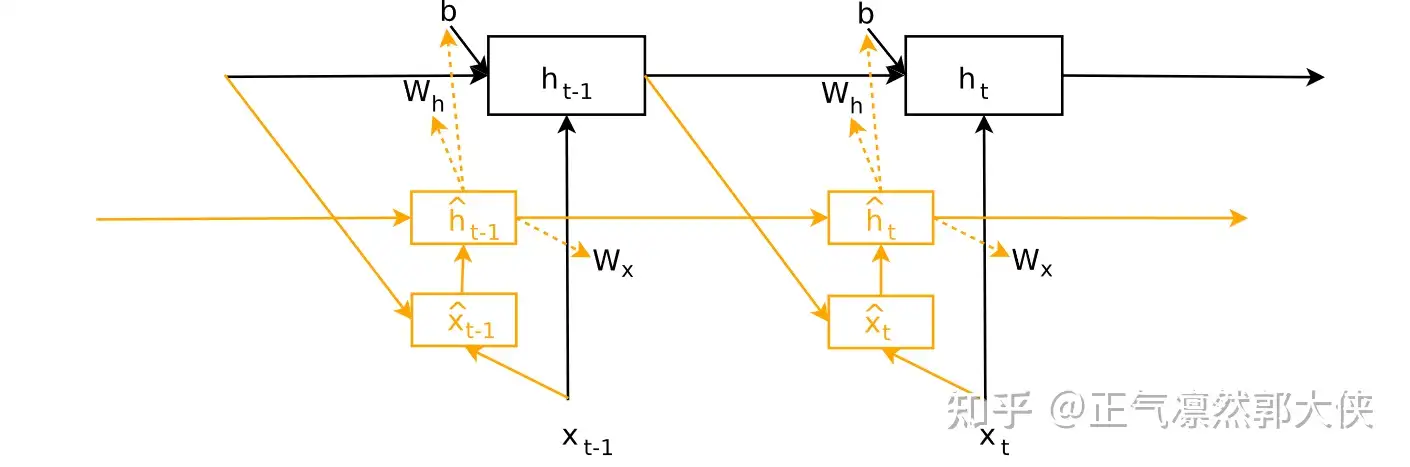
ADAPTIVE WEIGHT GENERATION FOR RECURRENT NETWORKS
!(data/attachment/forum/202307/01/131930bg37437z0b0hb1hr.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/300 "image.png")
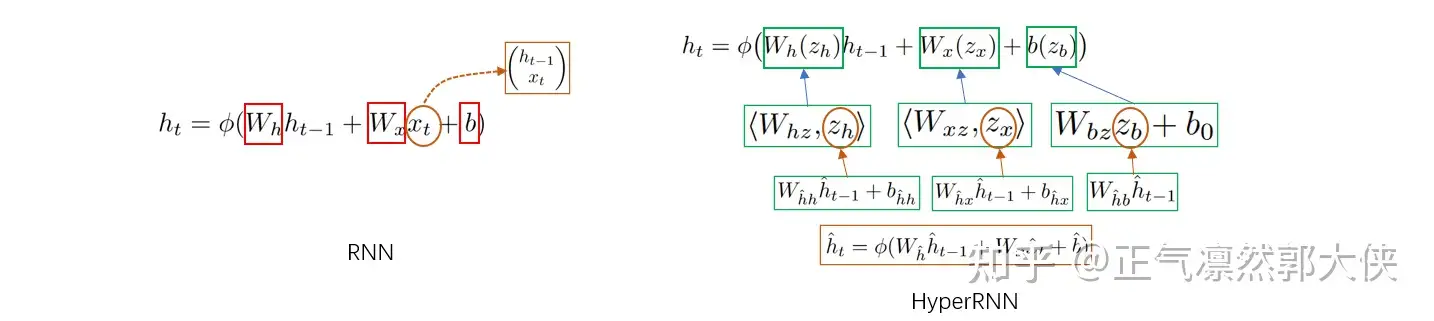
RNN与HyperRNN公式对比
从上面结构图和公式对比可以看出,HyperRNN自身也形成了RNN结构,这样原大模型RNN中不同层的参数是不一样的,并且可以通过调整超参数中参数的维度使得HyperRNN的参数量远低于原大模型的参数量。详细的参数计算就不写了,看论文吧,公式太多了,敲起来手疼。
## 3. 实验结果
实验部分针对静态超网络和动态超网络分别进行了多种任务的对比实验。包括针对静态超网络的图像识别,数据集为MNIST和CIFAR-10。针对动态超网络的语言模型和手写识别任务,数据集为Penn Treebank和Hutter Prize Wikipedia。
结果:hypernetwork:99.24%, baseline:99.28%,超网络参数是原模型1/3,效果却接近。
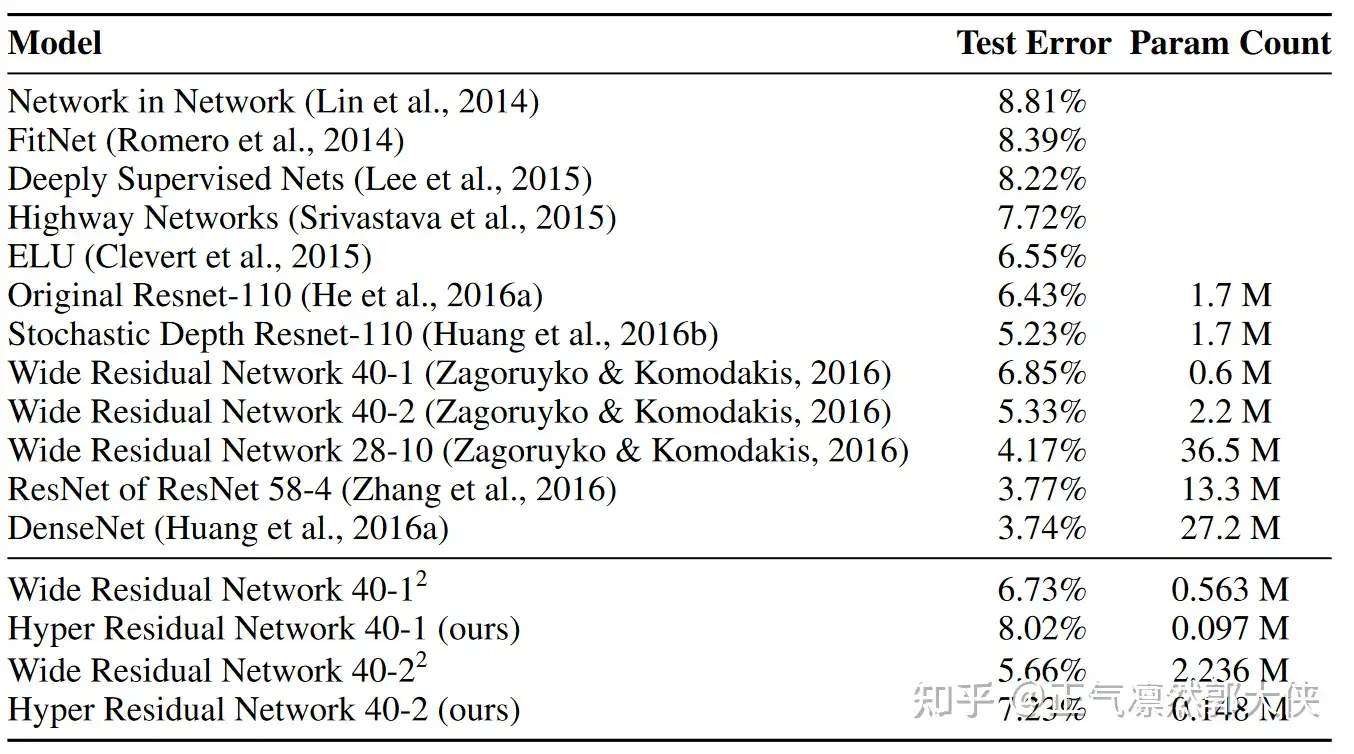
Table 2: CIFAR-10 Classification with hypernetwork generated weights.
结果:超网络参数是原模型1/6~1/15,效果相差2%。
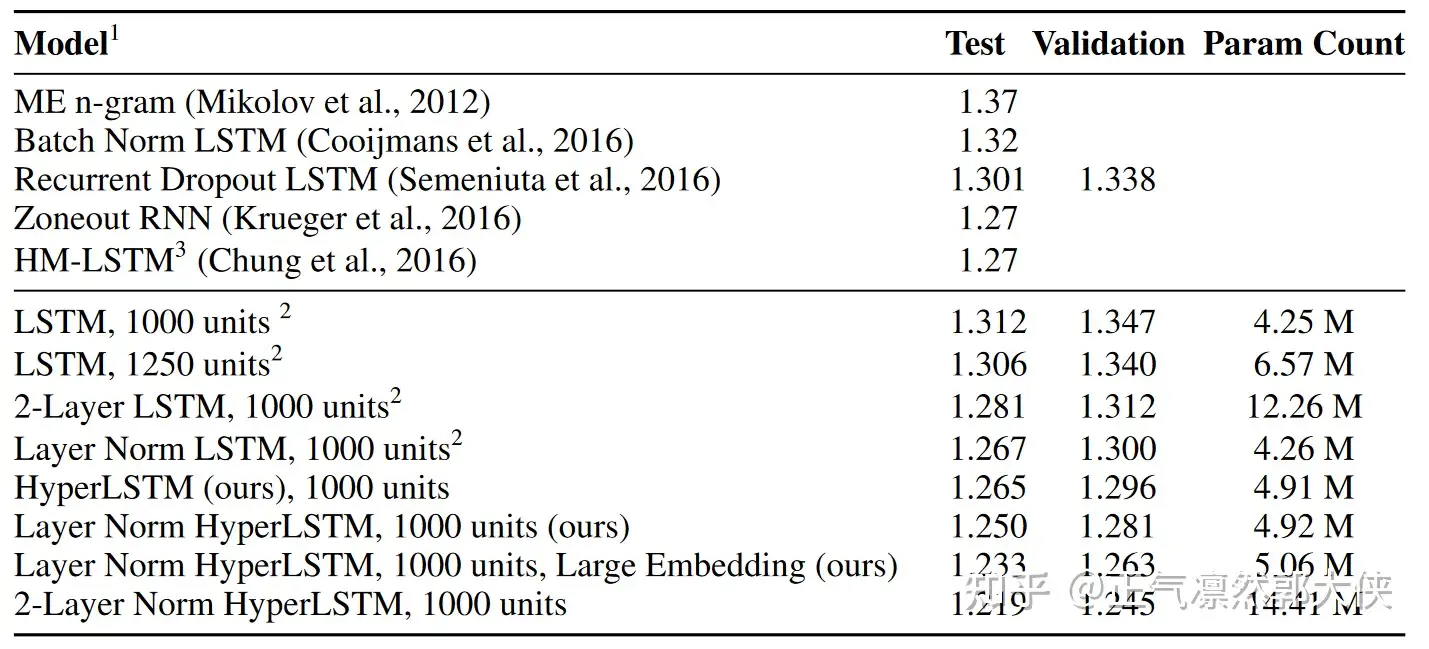
Table 3: Bits-per-character on the Penn Treebank test set.
结果:超网络参数如果和原模型相近,效果略高。
动态超网络方面的结果为:
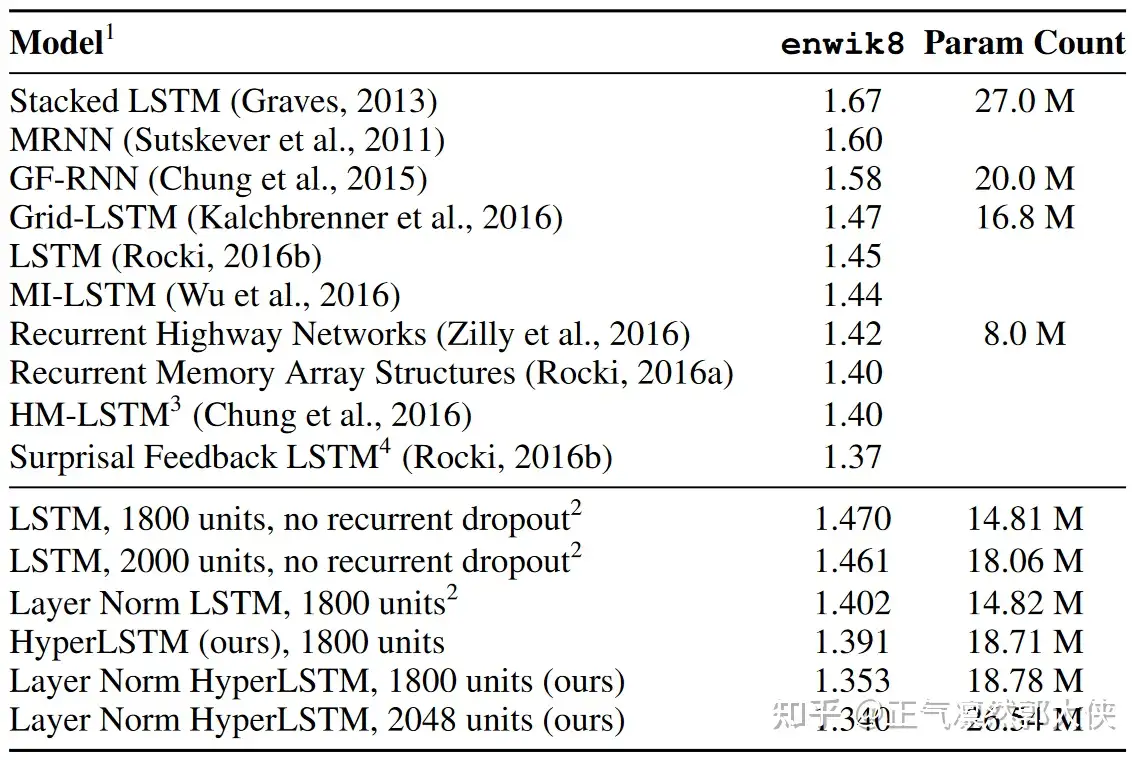
Table 4: Bits-per-character on the enwik8 test set.
结果:超网络参数如果和原模型相近,效果略高。
在翻译任务上:

Table 6: Single model results on WMT En→Fr (newstest2014)
结果:超网络参数如果和原模型相近,效果略高。
## 4. 写在最后
能看到这里的,也算是一种认可了,感谢啦~,ps记得点赞收藏。
感谢分享
页:
[1]